|
I am an EECS M.S. student at UC Berkeley advised by Professor Alexei Efros and Professor Jitendra Malik at Berkeley Artificial Intelligence Research (BAIR). I graduated with honors from UC Berkeley with a Bachelor's in CS + Statistics in May 2024. Currently, I work on generative world models at NVIDIA Research. Previously, I worked on foundation models at Apple AI/ML. Feel free to reach out to chat about research / potential collaborations. Email / LinkedIn / Github / Google Scholar |

|
|
I'm broadly interested in deep learning, generative models, and physical AI. Specifically, I'm interested in scaling deep learning with principled techniques that efficiently utilize data and compute. |

|
NVIDIA, arXiv, 2025 project page / arXiv / code / keynote / press: New York Times, Wall Street Journal, Fortune, TechCrunch, Forbes, Wired, BBC Generative world foundation models for data-driven simulation of physical AI systems. |

|
NVIDIA: Zeeshan Patel (Lead Contributor), arXiv / technical blog / code Open-source video foundation model training framework, providing accelerated video dataset curation, multimodal dataloading, and parallelized video diffusion model training and inference. |
|
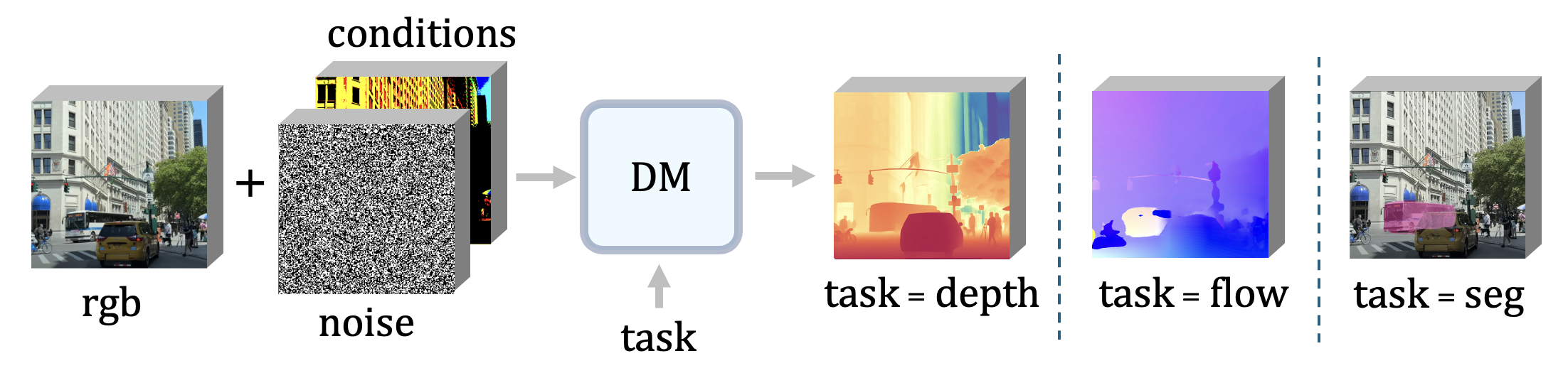
Zeeshan Patel*, Rahul Ravishankar*, Jathushan Rajasegaran, Jitendra Malik CVPR 2025 project page / arXiv / code Iterative computation with diffusion models offers a powerful paradigm for not only generation but also visual perception tasks. We unify tasks such as depth estimation, optical flow, and segmentation under image-to-image translation, and show how diffusion models benefit from scaling training and test-time compute for these perception tasks. |

|
Zeeshan Patel*, James DeLoye, Lance Mathias Preprint, 2024 arXiv We explore diffusion and flow matching models under the theoretical framework of generator matching. Our analysis offers a fresh perspective on the relationships between these state-of-the-art generative modeling paradigms and how to build new generative Markov processes that benefit from both approaches. |
|
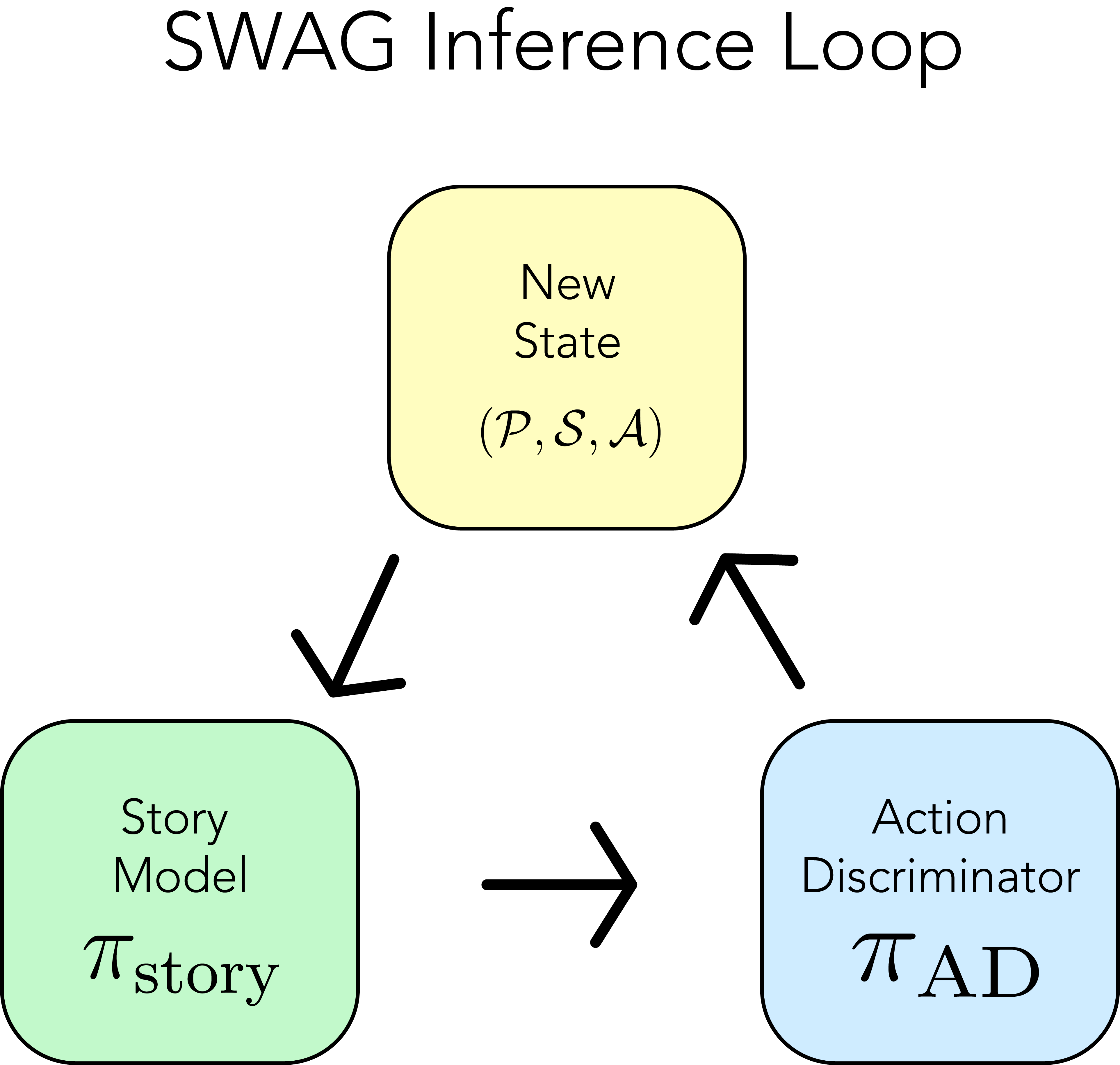
Zeeshan Patel*, Jonathan Pei*, Karim El-Refai*, Tianle Li EMNLP, 2024 arXiv We introduce Storytelling With Action Guidance (SWAG), a novel approach to storytelling with LLMs. Our approach reduces story writing to a search problem through a two-model feedback loop. SWAG can optimize open-sourced LLMs to substantially outperform previous end-to-end story generation techniques leveraging closed-source models. |
|
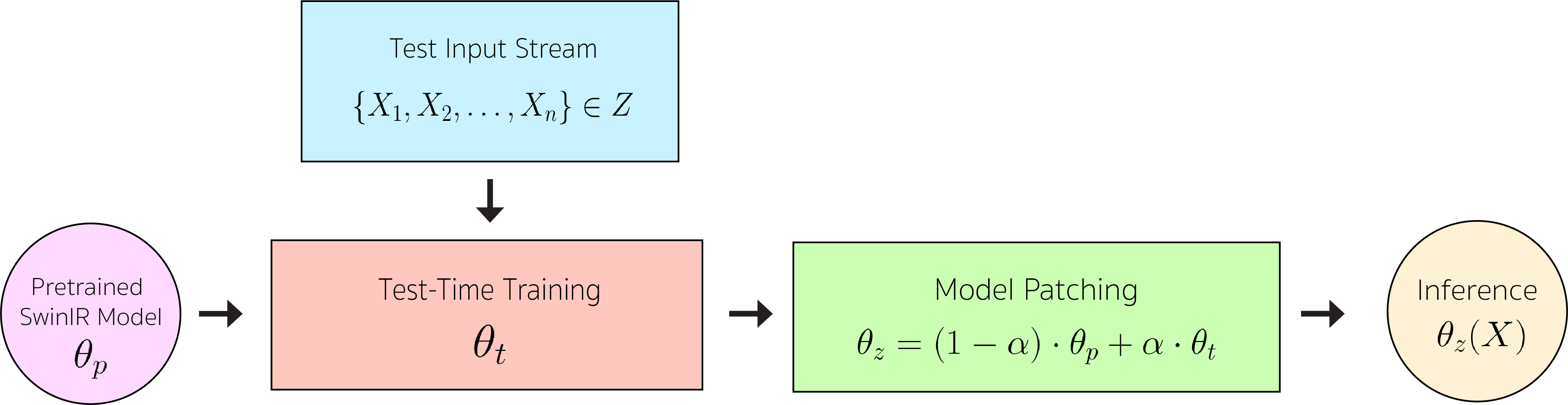
Zeeshan Patel*, Yossi Gandelsman Preprint, 2023 paper / code We present a self-supervised test-time training approach for fine-tuning image superresolution models to adapt to new test distributions on-the-fly. |
Template by Jon Barron.